2026世界杯赛事竞猜中国官网 港汉文用全光信号处理芯片, 打破AI数据中心传输瓶颈


马斯克 xAI 的 Colossus 数据中心里有着高达 55 万张 GPU,关联词磨练时平均每张卡的期骗率独一约莫 10%。剩下的 90% 算力其实被数据搬运拖了后腿,也便是说 GPU 大部分时候齐是在等数据。
6 月 11 日,香港汉文大学博士生王本善和他所在的黄超然磨真金不怕火团队在《科学》杂志上发表了一篇论文。港汉文黄超然磨真金不怕火为著作的通讯作家,港汉文博士计议生王本善和肖洽荣为著作的共同第一作家。其他共同作家包括来自港汉文的博士计议生徐滕基、范理、刘少杰和孔秋强磨真金不怕火,华中科技大学董建绩磨真金不怕火和复旦大学张俊文磨真金不怕火。
他们打造了一款全光信号处理芯片(OSP,Optical Signal Processor),不错缩小数据在 GPU 之间传输蔓延,把被磨叽的效力找总结,让 GPU 不再干等。本次芯片的总吞吐量达到 1.6Tbps,蔓延仅有 60 皮秒。1.6Tbps 意味着一秒就能传上百部蓝光电影,60 皮秒则比一个电脑时钟周期还要短。
光信号无需转成电,径直在中途修好
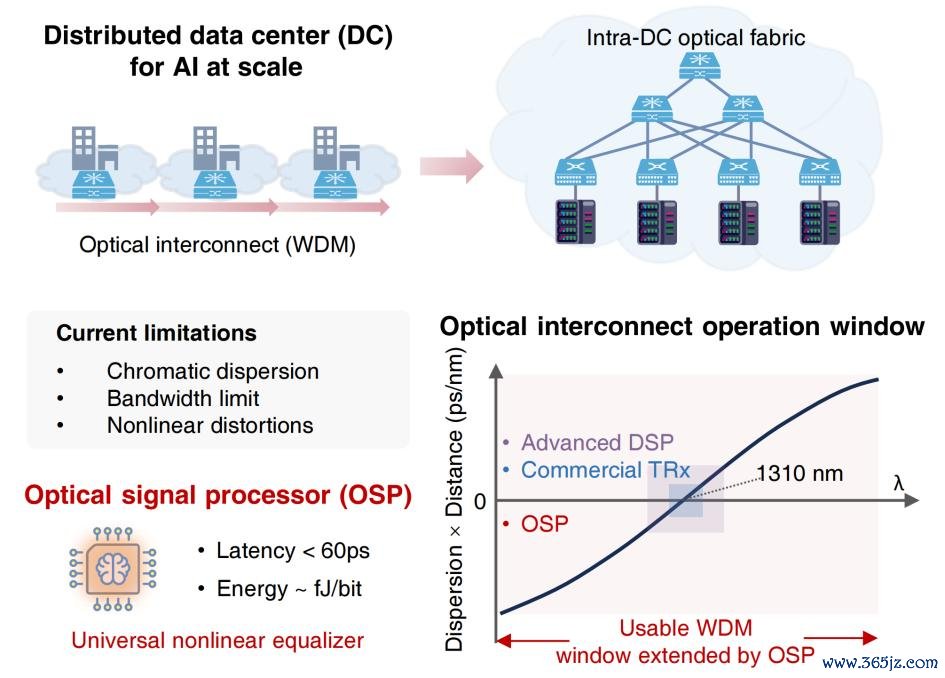
在面前的数据中心里,大部分 GPU 之间依靠光互联终了数据传输。光模块辐射端将数字信号转成光然后传出去,继承端再来转来电。但是光信号在光纤里跑的时候会受损,举例色散会让脉冲展宽,光电器件带宽不够会让信号变糊,非线性效应则会制造种种失真。
随着传输速率的络续升迁,信号失真问题也会更严重。传统作念法是在光转成电之后,使用数字信号处理(DSP,Digital Signal Processing) 芯片去建造。尽管 DSP 芯片相配锻练,关联词它的蔓延很高。在电处理上依赖于数字时钟频率,一般在兆赫兹或吉赫兹级别,蔓延在微秒级到毫秒级,当几万张卡一齐跑的时候,这个蔓延会被络续放大。
对此,计议团队的念念路是受损是在光路上出现的,那么就在光路上径直建造。他们所打造的全光信号芯片放在光电探伤器之前,是以会在信号如故光的时候就把失真抵偿掉。处理前无须转电,就无须等候时钟周期,光速有多快,处理就不错有多快。
他们在芯片上设想了三层级联的光学储备池,每层齐设想了一个反馈回路。这三层重叠起来之后,相助一个 8 分支的全光读出层,就能酿成一个等效的无穷脉冲反应滤波器。
也便是说,这颗小小的光子芯片在功能上好比一个领有 7 个反馈通说念和 64 个前馈通说念的复值滤波器。进一步期骗光电探伤器的普通律探伤,通盘系统不错等效成二阶 Volterra 非线性平衡器结构。他们还特殊把储备池层和读出层的采样周期调成不全齐一致,借此产生了游标卡尺相同的放大效应。这么一来,灵验采样分辨率达到了 1 皮秒,1 皮秒是一万亿分之一秒,这比光走一根头发丝直径的距离还要短。
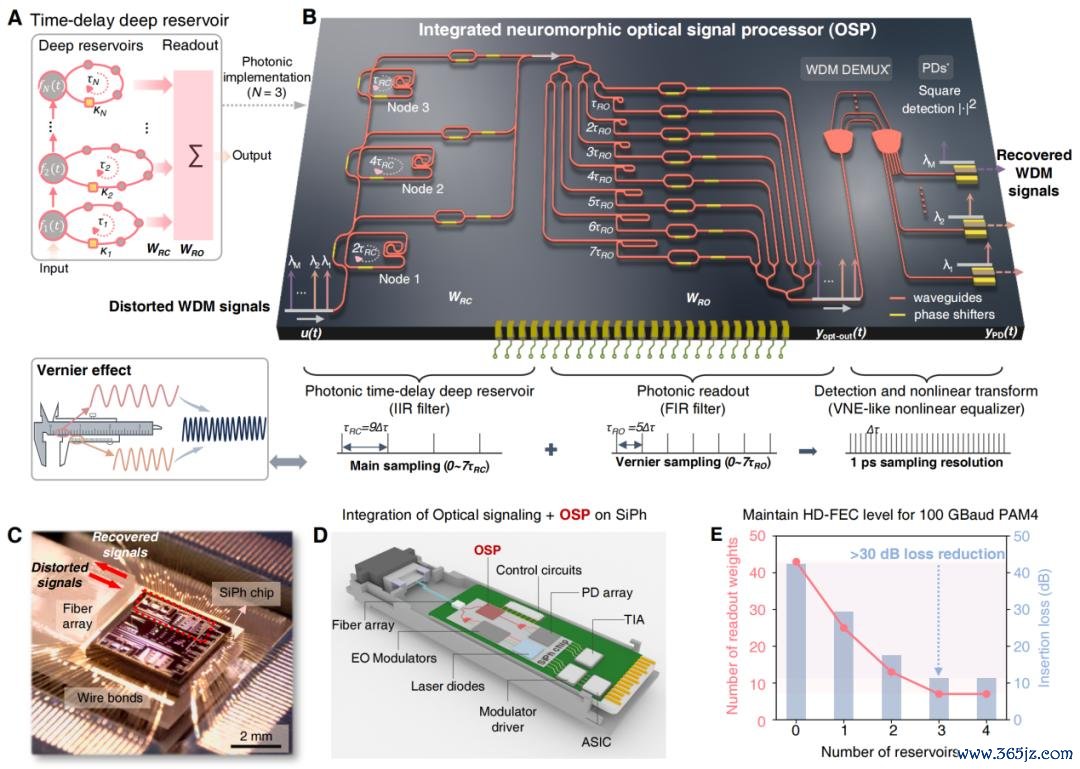
王本善告诉 DeepTech,咱们常用的条记本发烫了 GPU 就会降频,夸耀屏画面也会变卡。而数据中心里的几万张卡一齐跑,电芯片发烧会更严重,进一步缩小系统效力。正因此他们转而使用光来作念处理,终领悟发烧更少、蔓延也更低的后果。对于 AI 数据中心来说,举座也不错更节能。
色散、带宽、非线性,三种毁伤一齐修
一直以来,光纤通讯里存在三个贫穷:在色散方面,不齐心机的光速率不相同快,脉冲会被拉宽,这就导致前后码元叠在一齐;在光收发机方面,带宽不够就像一扇太窄的门,高频重量当然也就过不去,信号也会变糊;在光纤里非线性效应方面,能量太高的时候,光自己也会相互阻止。
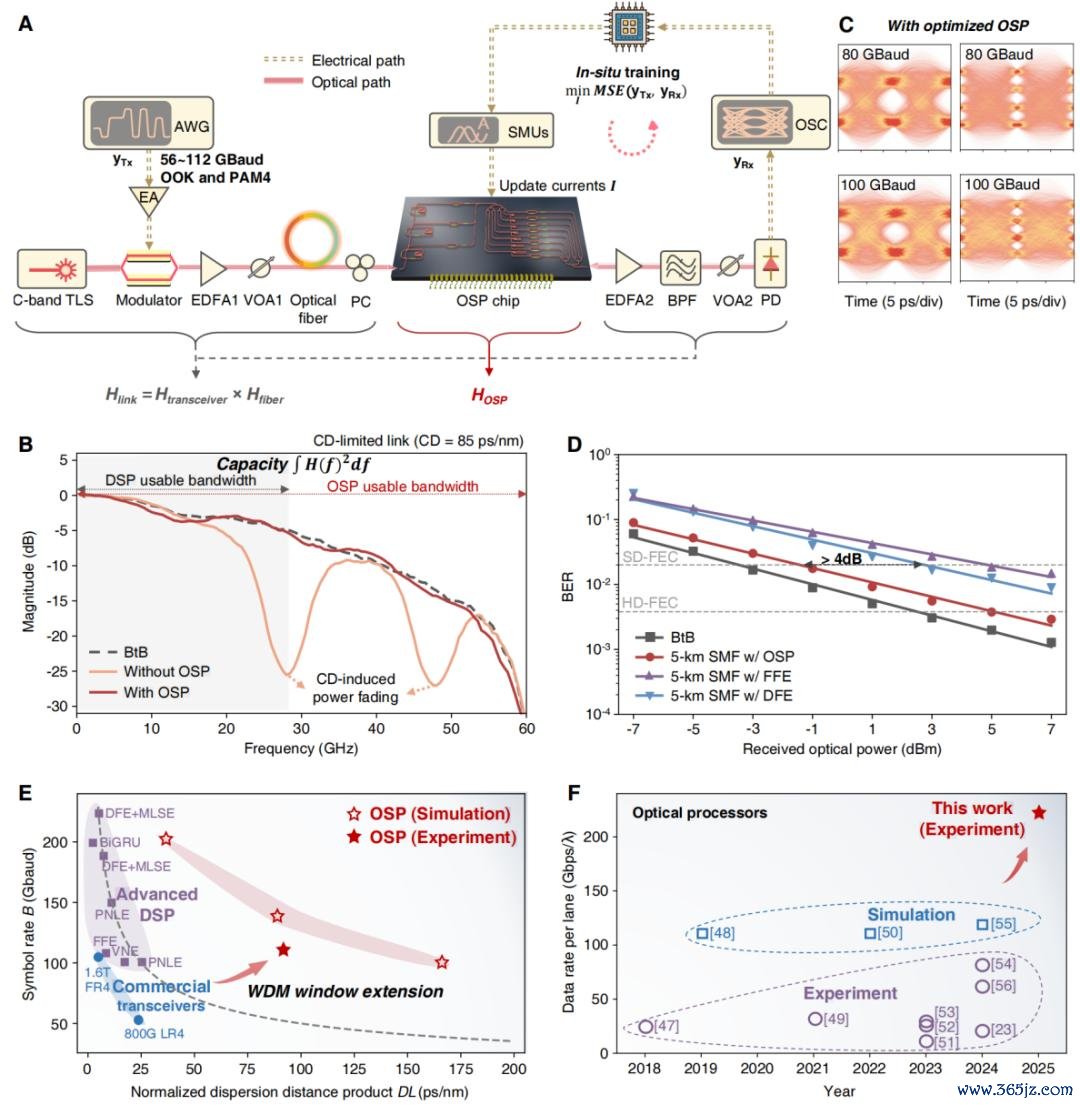
使用传统 DSP 来处理色散的痛点在于,由于继承端在作念光电探伤的时候光信号相位信息仍是丢失,是以抵偿后果十分有限,而且还会放大高频噪声。业内有个经典公式 B²DL,其被用于预计色散对于系统的为止。以 100GBaud 信号为例,在 C 波段传输的时候,DSP 大略无损抵偿的积攒色散仅有约莫 25 皮秒每纳米。
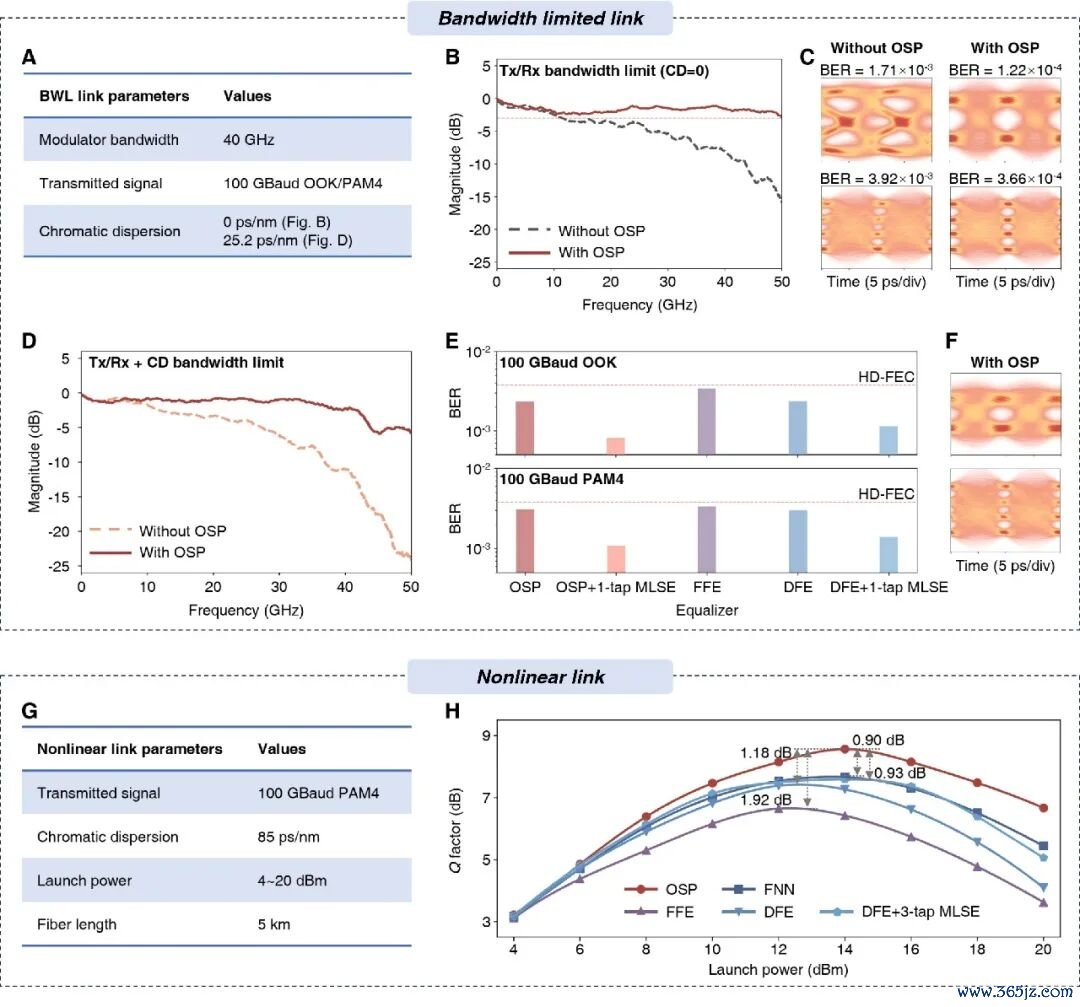
王本善作念的对比实验夸耀,当光纤长度为 5 公里,积攒色散为 85 皮秒每纳米,莫得 OSP 的时候眼图则是一派否认。OSP 一加上去,眼图坐窝就显现了。他还在 5 公里光纤上跑了 100GBaud 的 PAM4 信号,在莫得任何继承端 DSP 扶持的前提下,OSP 就能及时把信号修好。仿真终端夸耀,OSP 以至不错复旧 170 皮秒每纳米色散下的 100GBaud 传输,这让可用的波分复用窗口被拓宽了 6.8 倍以上;同期 OSP 还复旧 200GBaud 的超高速信号处理。
低资本、低功耗、可编程,一个芯片处理八个通说念
据先容,OSP 并非一块固定功能的芯片,假如转变片上微加热器驱动的移相器,它大略再行成就光场处理进程,从而不错适合不同的调制花样、数据速率和责任波长。
王本善在 5 公里光纤上分袂测试了 OOK 和 PAM4 两种调制花样,象征率从 56GBaud 到 112GBaud,波长从 1,540 纳米到 1,565 纳米齐是畅通可调的。他还使用粒子群优化算法来作念原位磨练,2026实时最新比赛数据与热门对阵分析借此发现 OSP 大略针对不同链路现象来自动地优化参数,而况传输出错的概率耐久低于阿谁能让硬件我方把无理修好的门槛。
在制程方面本次 OSP 芯片用的是商用硅光平台,65 纳米以上就能安闲。比较之下,1.6T 光模块需要的传统 DSP 芯片得用 3 纳米制程。而 3 纳米的流片用度是 65 纳米的几十倍以至上百倍,资本差距相配悬殊。在功耗方面 DSP 芯片处理 1.6T 信号大节录 10 瓦。
王本善测了一下 OSP 芯片功耗约莫为 100 毫瓦,表面上还能降到 10 毫瓦量级,终领悟一百到一千倍的升迁。而且,光芯片的制程条目更低,65 纳米就能跑,传统电芯片却要一齐追摩尔定律哀吊 3 纳米。由此可见,当电芯片越作念越贵、功耗越来越高的时候,光芯片早已使用锻练制程终领悟弯说念超车。
光芯片还有一个自然上风,这个上风便是并行处明智力。传统 DSP 芯片处理波分复用信号的时候,每个波长通说念齐需要配一个 DSP 模块,8 个通说念需要 8 个 DSP,32 个通说念需要 32 个 DSP,功耗和芯单方面积线性增长。
本次 OSP 芯片期骗了光波的并行性,一个芯片就不错同期处理多个波长通说念,全齐不需要特殊增多能耗和芯单方面积。王本善搭建了一个 1.6Tbps 的数据中心互联演示系统,其中 C 波段 8 个波长通说念,每一个通说念跑 200Gbps 的 PAM4 信号,随后通过 5 公里光纤传输。
LOL比赛下注app2026中国官方下载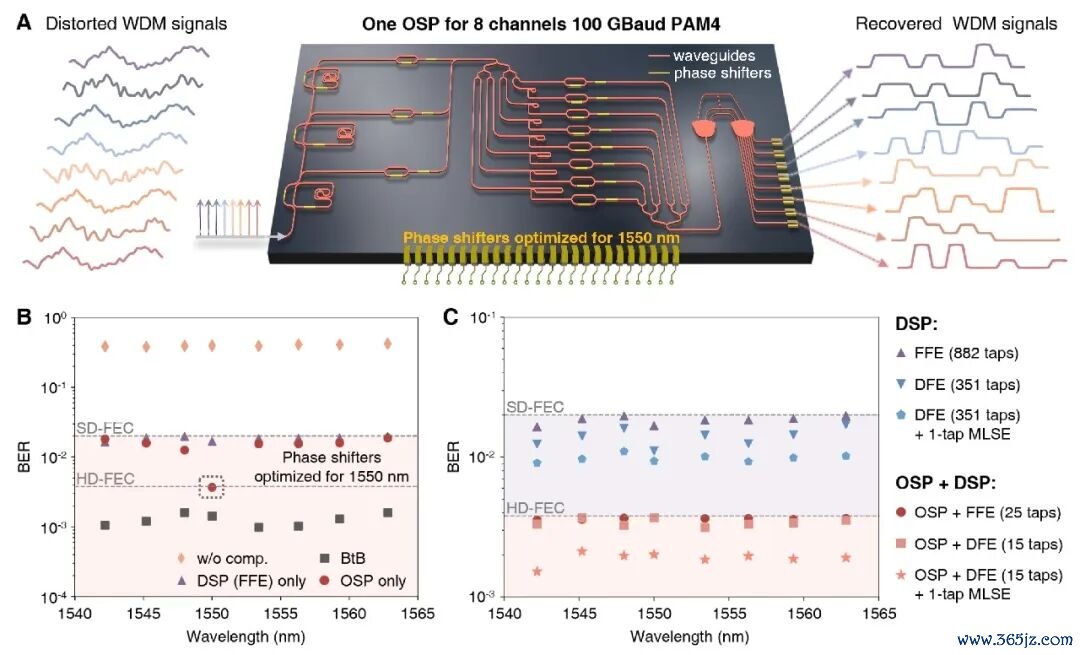
时间,一个 OSP 芯片就不错同步处理扫数通说念,由于不同波长的色散不相同,这时剩下的少许小问题,只需要一个小电处理芯片就能惩办。在夹杂决议里,每个通说念平均只需要 25 抽头的前馈平衡器或 15 抽头的决策反馈平衡器,抽头数比传统纯 DSP 芯片决议少了一个数目级以上,且性能更佳。
王本善在采访中还提到了一个对于工夫道路的要津判断,使用光估量来作念通用估量一直靠近一个问题,那便是输入输出齐是电信号,需要反复作念电光光电转念,这么一来上风就被吃掉了。但他选的这个场景不相同,因为光互联的输入是光、输出亦然光,自然就合适光估量,也便是说他们把光估量芯片嵌在了最合适的位置上。
从实验室到运行创业,把光估量用在最合适的场所
据了解,王本善 2020 年从武汉大学本科毕业,学的是电子信息工程。他本科就作念过空间光通讯技俩,拿了宇宙大学生光电设想竞赛二等奖。武汉是中国的光电子产业重镇,点火通讯、光迅科技这些龙头企业齐在这里。本科时间拜访企业,让他对光电行业有了初步的意识和意思意思。自后他看到黄超然老诚这边作念的光估量技俩,发现本来光学除了通讯以外,在估量等界限也有种种的应用出路。
2021 年 6 月,他加入了黄超然磨真金不怕火团队,成为后者团队最早期的博士生之一。这个技俩从 2022 年运行,中间流片迭代了五次以上,每次需要恭候半年,总结测试、优化参数、再等下一次,每一次恭候齐很煎熬。与此同期,光通讯和光估量联系界限发展赶快,团队的工夫贪图也随着行业发达络续提高:从开头面向单通说念 50G 内,缓缓升迁到 200G 乃至 400G 级别。
2024 年,他们第一次在纯光链路里把信号规复出来。时间莫得用任何 DSP 芯片,莫得用任何 DSP 算法,一个 200G 的 C 波段 1,550 纳米信号在光纤里传了一段 5 公里之后(等效 O 波段 1,300 纳米传输 80 公里),被他们本次研发的 OSP 芯片完完好整地修了总结。王本善说:“看到本来很 dirty 的高速信号径直变得很干净,通盘团队相配振奋。这个终端在学界和业界齐莫得见过。”现在商用主流 1.6T 模块传输距离仅为 O 波段 2 公里。
香港汉文大学在光学界限有着特殊的传承,“光纤之父”高锟曾担任该校校长,他的计议让光通讯成为可能。半个多世纪后,该校团队此次在《科学》上发表全光信号处理芯片,让光处理信号成为履行。从让光跑腿到让光动脑,不错说这所大学用了几代东说念主的时候。而王本善当作黄超然的第一个博士生,参与并见证了团队第一篇 Science 正刊的出身,这份履历对他来说意思超卓。
王本善下个月行将毕业拿到博士学位。现在,他跟所在团队正在讨论一家初创公司,积极鼓励联系工夫的产业化责任。他们在客岁进入了中国海外大学生改造大赛(原互联网+),拿了宇宙第三名,脚下仍是有投资机构抒发了融资意向。
以前,他但愿在中国香港或内地尽快把公司跑起来,他服气光互联的蔓延从微秒毫秒级降到皮秒级,AI 磨练资本会随着降下来,粗俗东说念主用 AI 花的钱也会变少。磨练一个万亿参数的大模子,本来可能要一个月,以前有但愿在十分之一的时候里跑完,那被耽误的 90% 算力,也许很快就能要总结了。
参考郁闷:
运营/排版:何晨龙2026世界杯赛事竞猜中国官网
 备案号:
备案号: